FFT(高速フーリエ変換)は結構時間のかかる処理だったのですが、numpyとPyQtGraphを使うと高速に動作します。
Matplotlibでやった人がいましったが、動作が遅いようです。
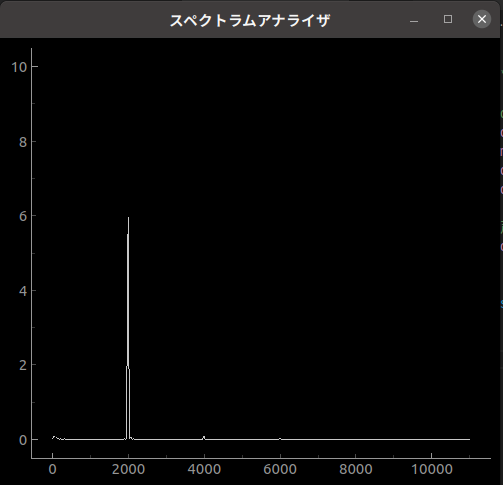
Audacityで2000Hzの正弦波をスピーカから出力し、マイクで入力しました。
ちょうど2000Hzのところにピークがでています。
ソースです。
# -*- coding:utf-8 -*-
#pyqtgraph関係のライブラリ
import pyqtgraph as pg
from pyqtgraph.Qt import QtCore, QtGui
import numpy as np
import sys
#音声関係のライブラリ
import pyaudio
class DrawFFT:
def __init__(self):
#プロット初期設定
self.win=pg.GraphicsWindow(size=(500, 450), show=True)
self.win.setWindowTitle(u"スペクトラムアナライザ")
self.plt=self.win.addPlot() #プロットのビジュアル関係
self.plt.setYRange(0,10) #y軸の上限、下限の設定
self.curve=self.plt.plot() #プロットデータを入れる場所
self.received = False
#マイクインプット設定
self.CHUNK=1024 #1回の受信で読み取るデータ量
self.RATE=22050 #サンプリング周波数
self.audio=pyaudio.PyAudio()
self.stream=self.audio.open(format=pyaudio.paInt16,
channels=1,
rate=self.RATE,
input=True,
frames_per_buffer=self.CHUNK,
stream_callback=self.callback)
self.stream.start_stream()
#アップデート時間設定
self.timer=QtCore.QTimer()
self.timer.timeout.connect(self.update)
self.timer.start(10)
#音声データの格納場所(プロットデータ)
self.data=np.zeros(self.CHUNK)
# x軸
wave_x = np.linspace(0, self.RATE, self.CHUNK)
self.chunk2 = int(self.CHUNK/2)
self.wave_x2 = wave_x[0:self.chunk2]
self.win_hamming = np.hamming(self.CHUNK)
# デストラクタ
def __del__(self):
print('terminated.')
self.stream.stop_stream()
self.stream.close()
self.audio.terminate()
def callback(self, in_data, frame_count, time_info, status):
self.data=np.frombuffer(in_data, dtype="int16")/32768.0
self.received = True
return (in_data,pyaudio.paContinue)
def update(self):
if self.received == True:
# FFT
wave_y = np.fft.fft(self.data * self.win_hamming)
wave_y = np.abs(wave_y)
wave_y2 = wave_y[0:self.chunk2]
self.curve.setData(self.wave_x2, wave_y2) #プロットデータを格納
self.received = False
if __name__=="__main__":
plotwin=DrawFFT()
if (sys.flags.interactive!=1) or not hasattr(QtCore, 'PYQT_VERSION'):
QtGui.QApplication.instance().exec_()
クラスを使ってコーディングしました。
クラスを使えばデストラクタによりオブジェクトのクローズな後始末をまとめてできます。
# デストラクタ
def __del__(self):
print('terminated.')
self.stream.stop_stream()
self.stream.close()
self.audio.terminate()
また
、PyAudioではデータの取り込み完了で呼び出されるコールバック関数を使うと無駄のない処理ができます。
FFTの実装は、タイマーのところで処理しています。
def update(self):
if self.received == True:
# FFT
wave_y = np.fft.fft(self.data * self.win_hamming)
wave_y = np.abs(wave_y)
wave_y2 = wave_y[0:self.chunk2]
self.curve.setData(self.wave_x2, wave_y2) #プロットデータを格納
self.received = False
FFTの処理
wave_y = np.fft.fft(self.data * self.win_hamming)
実測データにハミング窓を掛けて演算します。
wave_y2 = wave_y[0:self.chunk2]
はFFTをした半分を使っています。(サンプリング定理)
|

